
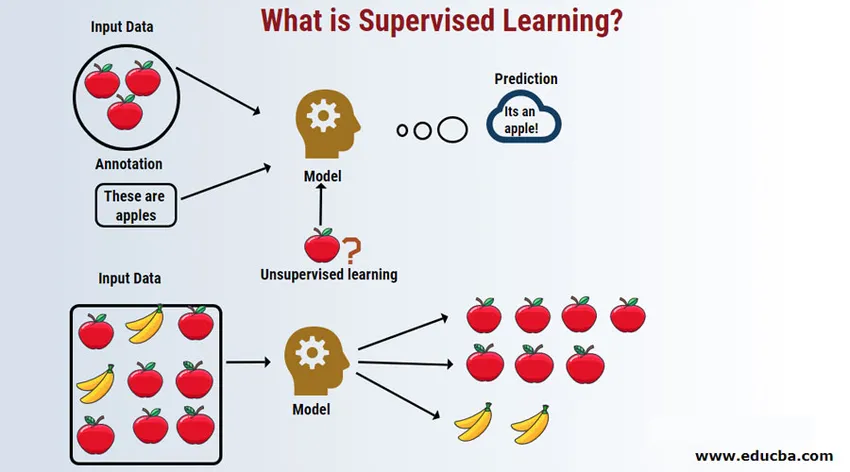
Introdução à Aprendizagem Supervisionada
O Aprendizado Supervisionado é uma área de aprendizado de máquina na qual trabalhamos na previsão de valores usando conjuntos de dados rotulados. Os conjuntos de dados de entrada rotulados são chamados de variáveis independentes, enquanto os resultados previstos são chamados de variáveis dependentes porque eles dependem da variável independente para seus resultados. Por exemplo, todos temos uma pasta de spam em nossa conta de e-mail (por exemplo, Gmail), que detecta automaticamente a maioria dos e-mails de spam / fraude para você com precisão superior a 95%. Ele funciona com base em um modelo de aprendizado supervisionado, no qual temos um conjunto de dados rotulados de treinamento, que neste caso é um email de spam rotulado sinalizado pelos usuários. Esses conjuntos de treinamento são usados para aprendizado, que posteriormente serão usados para a categorização de novos emails como spam, se ele se encaixar na categoria.
Trabalhando no aprendizado supervisionado de máquinas
Vamos entender o aprendizado de máquina supervisionado com a ajuda de um exemplo. Digamos que temos uma cesta de frutas que é preenchida com diferentes espécies de frutas. Nosso trabalho é categorizar as frutas com base em sua categoria.
No nosso caso, consideramos quatro tipos de frutas: maçã, banana, uva e laranja.
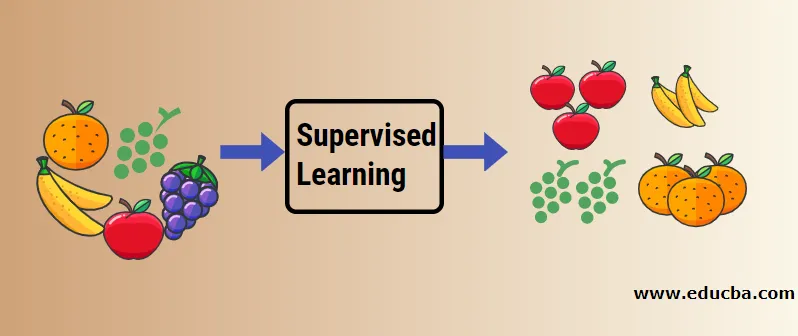
Agora, tentaremos mencionar algumas das características únicas dessas frutas que as tornam únicas.
|
S No. | Tamanho | Cor | Forma |
Primeiro nome |
|
1 | Pequeno | Verde | Redondo a oval, forma de cacho cilíndrico |
Uva |
|
2 | grande | Vermelho | Forma arredondada com depressão no topo |
maçã |
|
3 | grande | Amarelo | Cilindro de curvatura longo |
Banana |
| 4 | grande | laranja | Forma arredondada |
laranja |
Agora, digamos que você pegou uma fruta da cesta de frutas, examinou suas características, por exemplo, forma, tamanho e cor, por exemplo, e deduz que a cor dessa fruta é vermelha, o tamanho se for grande., a forma é arredondada, com depressão na parte superior; portanto, é uma maçã.
- Da mesma forma, você faz o mesmo para todas as outras frutas restantes.
- A coluna mais à direita ("Nome da fruta") é conhecida como variável de resposta.
- É assim que formulamos um modelo de aprendizado supervisionado, agora será bem fácil para qualquer pessoa nova (digamos, um robô ou um alienígena) com determinadas propriedades agrupar facilmente o mesmo tipo de frutas.
Tipos de algoritmo de aprendizado de máquina supervisionado
Vamos ver diferentes tipos de algoritmos de aprendizado de máquina:
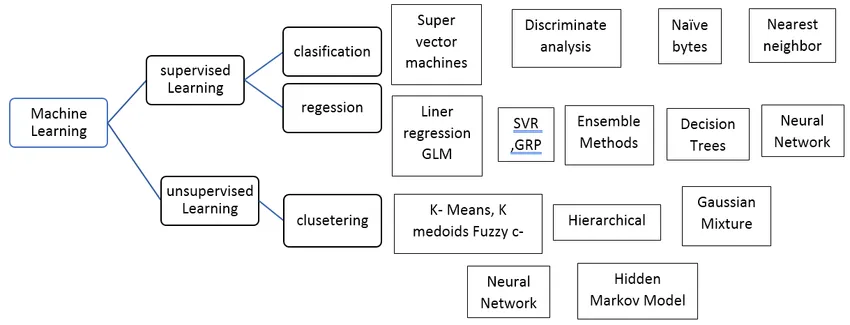
Regressão:
A regressão é usada para prever a saída de valor único usando o conjunto de dados de treinamento. O valor de saída é sempre chamado como variável dependente, enquanto as entradas são conhecidas como variável independente. Temos diferentes tipos de regressão no aprendizado supervisionado, por exemplo,
- Regressão linear - Aqui temos apenas uma variável independente que é usada para prever a saída, ou seja, variável dependente.
- Regressão múltipla - Aqui temos mais de uma variável independente que é usada para prever a saída, ou seja, a variável dependente.
- Regressão polinomial - Aqui, o gráfico entre as variáveis dependentes e independentes segue uma função polinomial. Por exemplo, a princípio, a memória aumenta com a idade, depois atinge um limite em uma certa idade e começa a diminuir à medida que envelhecemos.
Classificação:
A classificação dos algoritmos de aprendizado supervisionado é usada para agrupar objetos semelhantes em classes únicas.
- Classificação binária - Se o algoritmo está tentando agrupar 2 grupos distintos de classes, é chamado de classificação binária.
- Classificação multiclasse - Se o algoritmo estiver tentando agrupar objetos em mais de 2 grupos, será chamado de classificação multiclasse.
- Força - Os algoritmos de classificação geralmente funcionam muito bem.
- Desvantagens - Propenso a sobreajuste e pode ser irrestrito. Por exemplo - Classificador de spam por email
- Regressão / classificação logística - Quando a variável Y é uma categórica binária (ou seja, 0 ou 1), usamos regressão logística para a previsão. Por exemplo : prever se uma determinada transação de cartão de crédito é fraudulenta ou não.
- Classificadores Naïve Bayes - O classificador Naïve Bayes é baseado no teorema bayesiano. Esse algoritmo geralmente é mais adequado quando a dimensionalidade das entradas é alta. Consiste em gráficos acíclicos que possuem um nó pai e muitos filhos. Os nós filhos são independentes um do outro.
- Árvores de Decisão - Uma árvore de decisão é um gráfico de árvore, como uma estrutura que consiste em um nó interno (teste no atributo), ramo que indica o resultado do teste e os nós folha que representam a distribuição das classes. O nó raiz é o nó superior. É uma técnica muito usada e usada para classificação.
- Máquina de vetores de suporte - Uma máquina de vetores de suporte é ou um SVM realiza a tarefa de classificação localizando o hiperplano que deve maximizar a margem entre duas classes. Essas máquinas SVM estão conectadas às funções do kernel. Os campos onde os SVMs são amplamente utilizados são biometria, reconhecimento de padrões etc.
Vantagens
Abaixo estão algumas das vantagens dos modelos supervisionados de aprendizado de máquina:
- O desempenho dos modelos pode ser otimizado pelas experiências do usuário.
- O aprendizado supervisionado produz resultados usando a experiência anterior e também permite coletar dados.
- Algoritmos de aprendizado de máquina supervisionados podem ser usados para implementar uma série de problemas do mundo real.
Desvantagens
As desvantagens do aprendizado supervisionado são as seguintes:
- O esforço de treinar modelos de aprendizado de máquina supervisionados pode levar muito tempo se o conjunto de dados for maior.
- A classificação de big data às vezes apresenta um desafio maior.
- Pode ser necessário lidar com os problemas de sobreajuste.
- Precisamos de muitos bons exemplos se queremos que o modelo tenha um bom desempenho enquanto treinamos o classificador.
Boas Práticas ao Construir Modelos de Aprendizado
É uma boa prática ao criar modelos de máquinas de aprendizado supervisionado: -
- Antes de construir qualquer bom modelo de aprendizado de máquina, o processo de pré-processamento de dados deve ser realizado.
- É preciso decidir o algoritmo que deve ser mais adequado para um determinado problema.
- Precisamos decidir que tipo de dados será usado para o conjunto de treinamento.
- Precisa decidir sobre a estrutura do algoritmo e função.
Conclusão
Em nosso artigo, aprendemos o que é aprendizado supervisionado e vimos que aqui treinamos o modelo usando dados rotulados. Depois, entramos no trabalho dos modelos e de seus diferentes tipos. Finalmente vimos as vantagens e desvantagens desses algoritmos supervisionados de aprendizado de máquina.
Artigos recomendados
Este é um guia para o que é aprendizado supervisionado? Aqui discutimos os conceitos, como funciona, tipos, vantagens e desvantagens do aprendizado supervisionado. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- O que é aprendizagem profunda
- Aprendizado supervisionado versus aprendizado profundo
- O que é sincronização em Java?
- O que é hospedagem na web?
- Maneiras de criar uma árvore de decisão com vantagens
- Regressão polinomial | Usos e Recursos