
Visão geral dos algoritmos de redes neurais
- Vamos primeiro saber o que significa uma Rede Neural? As redes neurais são inspiradas pelas redes neurais biológicas no cérebro ou podemos dizer o sistema nervoso. Isso gerou muita empolgação e ainda há pesquisas nesse subconjunto de Machine Learning na indústria.
- A unidade computacional básica de uma rede neural é um neurônio ou nó. Ele recebe valores de outros neurônios e calcula a saída. Cada nó / neurônio está associado ao peso (w). Esse peso é determinado de acordo com a importância relativa desse neurônio ou nó específico.
- Portanto, se considerarmos f como a função do nó, a função do nó f fornecerá a saída conforme mostrado abaixo: -
Saída do neurônio (Y) = f (w1.X1 + w2.X2 + b)
- Onde w1 e w2 são peso, X1 e X2 são entradas numéricas, enquanto b é o viés.
- A função acima f é uma função não linear também chamada função de ativação. Seu objetivo básico é introduzir a não linearidade, pois quase todos os dados do mundo real são não lineares e queremos que os neurônios aprendam essas representações.
Algoritmos de Redes Neurais Diferentes
Vamos agora analisar quatro algoritmos de redes neurais diferentes.
1. Descida de gradiente
É um dos algoritmos de otimização mais populares no campo de aprendizado de máquina. É usado durante o treinamento de um modelo de aprendizado de máquina. Em palavras simples, é basicamente usado para encontrar valores dos coeficientes que simplesmente reduzem a função de custo o máximo possível.Em primeiro lugar, começamos definindo alguns valores de parâmetros e, em seguida, usando o cálculo, começamos a ajustar iterativamente os valores para que a função perdida é reduzida.
Agora, vamos à parte o que é gradiente? Portanto, um gradiente significa muito que a saída de qualquer função mudará se diminuirmos a entrada pouco ou em outras palavras, podemos chamá-la de inclinação. Se a inclinação for íngreme, o modelo aprenderá mais rapidamente da mesma forma que um modelo para de aprender quando a inclinação é zero. Isso ocorre porque é um algoritmo de minimização que minimiza um determinado algoritmo.
Abaixo da fórmula para encontrar a próxima posição é mostrada no caso de descida de gradiente.
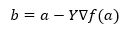
Onde b é a próxima posição
a é a posição atual, gama é uma função de espera.
Portanto, como você pode ver, a descida em gradiente é uma técnica muito sólida, mas há muitas áreas em que a descida em gradiente não funciona corretamente. Abaixo, alguns deles são fornecidos:
- Se o algoritmo não for executado corretamente, podemos encontrar algo como o problema do gradiente de fuga. Isso ocorre quando o gradiente é muito pequeno ou muito grande.
- Os problemas surgem quando o arranjo de dados apresenta um problema de otimização não convexo. Gradiente decente funciona apenas com problemas que são o problema otimizado convexo.
- Um dos fatores muito importantes a serem observados ao aplicar esse algoritmo são os recursos. Se tivermos menos memória atribuída para o aplicativo, devemos evitar o algoritmo de descida gradiente.
2. Método de Newton
É um algoritmo de otimização de segunda ordem. É chamado de segunda ordem porque faz uso da matriz hessiana. Portanto, a matriz hessiana nada mais é do que uma matriz quadrada de derivadas parciais de segunda ordem de uma função de valor escalar. No algoritmo de otimização de método de Newton, é aplicada à primeira derivada de uma função dupla diferenciável f, para que possa encontrar as raízes. / pontos estacionários. Vamos agora entrar nas etapas exigidas pelo método de Newton para otimização.
Primeiro, ele avalia o índice de perdas. Em seguida, verifica se o critério de parada é verdadeiro ou falso. Se falso, ele calcula a direção do treinamento de Newton e a taxa de treinamento e aprimora os parâmetros ou pesos do neurônio e, novamente, o mesmo ciclo continua. Portanto, agora você pode dizer que são necessários menos passos em comparação com a descida do gradiente para obter o mínimo valor da função. Embora tome menos etapas em comparação com o algoritmo de descida por gradiente, ainda não é amplamente utilizado, pois o cálculo exato do hessiano e seu inverso são computacionalmente muito caros.
3. Gradiente Conjugado
É um método que pode ser considerado como algo entre a descida do gradiente e o método de Newton. A principal diferença é que ela acelera a lenta convergência que geralmente associamos à descida do gradiente. Outro fato importante é que ele pode ser usado para sistemas lineares e não lineares e é um algoritmo iterativo.
Foi desenvolvido por Magnus Hestenes e Eduard Stiefel. Como já mencionado acima, ele produz convergência mais rápida que a descida do gradiente. A razão pela qual é possível fazê-lo é que, no algoritmo Conjugate Gradient, a pesquisa é feita juntamente com as direções do conjugado, pelas quais converge mais rapidamente que os algoritmos de descida do gradiente. Um ponto importante a ser observado é que γ é chamado de parâmetro conjugado.
A direção do treinamento é periodicamente redefinida para o negativo do gradiente. Este método é mais eficaz do que a descida de gradiente no treinamento da rede neural, pois não requer a matriz Hessiana que aumenta a carga computacional e também converte mais rapidamente que a descida de gradiente. É apropriado usar em grandes redes neurais.
4. Método quase-Newton
É uma abordagem alternativa ao método de Newton, como sabemos agora que o método de Newton é computacionalmente caro. Este método resolve essas desvantagens em uma extensão tal que, em vez de calcular a matriz de Hessian e depois calcular diretamente o inverso, esse método cria uma aproximação ao inverso de Hessian a cada iteração desse algoritmo.
Agora, essa aproximação é calculada usando as informações da primeira derivada da função de perda. Portanto, podemos dizer que é provavelmente o método mais adequado para lidar com redes grandes, pois economiza tempo de computação e também é muito mais rápido que o método de descida de gradiente ou gradiente conjugado.
Conclusão
Antes de terminarmos este artigo, vamos comparar a velocidade e a memória computacional dos algoritmos mencionados acima. Conforme os requisitos de memória, a descida em gradiente requer menos memória e também é a mais lenta. Ao contrário do que o método de Newton requer mais poder computacional. Portanto, levando tudo isso em consideração, o método Quasi-Newton é o mais adequado.
Artigos recomendados
Este foi um guia para algoritmos de redes neurais. Aqui também discutimos a visão geral do algoritmo de rede neural, juntamente com quatro algoritmos diferentes, respectivamente. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Aprendizado de máquina versus rede neural
- Estruturas de aprendizado de máquina
- Redes Neurais vs Deep Learning
- K- significa algoritmo de agrupamento
- Guia de classificação de redes neurais