

Introdução aos comandos Pig
O Apache Pig é uma ferramenta / plataforma usada para analisar grandes conjuntos de dados e executar longas séries de operações de dados. O porco é usado com o Hadoop. Todos os scripts pig internamente são convertidos em tarefas de redução de mapa e, em seguida, são executados. Ele pode lidar com dados estruturados, semiestruturados e não estruturados. Lojas de suínos, seu resultado no HDFS. Neste artigo, aprendemos mais tipos de comandos Pig.
Aqui estão algumas características do Pig:
- Auto-otimização: O Pig pode otimizar os trabalhos de execução, o usuário tem a liberdade de se concentrar na semântica.
- Fácil de programar: O Pig fornece um idioma / dialeto de alto nível, conhecido como Pig Latin, que é fácil de escrever. O Pig Latin fornece muitos operadores, que o programador pode usar para processar os dados. O programador também tem a flexibilidade de escrever suas próprias funções.
- Extensível: O Pig facilita a criação de funções personalizadas, chamadas UDFs (funções definidas pelo usuário), que tornam os programadores capazes de atingir qualquer requisito de processamento de maneira rápida e fácil. O script Pig é executado em um shell conhecido como grunhido.
Por que Comandos Pig?
Os programadores que não são bons em Java, geralmente enfrentam dificuldades para escrever programas no Hadoop, ou seja, na tarefa de reduzir mapas. Para eles, o Pig Latin, que é bastante parecido com a linguagem SQL, é um benefício. Sua abordagem de várias consultas reduz o comprimento do código.
Portanto, de maneira geral, sua maneira concisa e eficaz de programação. Os comandos Pig podem chamar código em várias linguagens como JRuby, Jython e Java.
A arquitetura dos comandos Pig
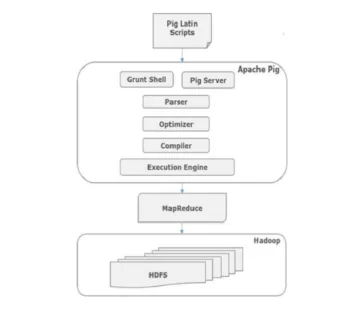
Todos os scripts escritos em Pig-Latin sobre grunt shell vão para o analisador para verificar a sintaxe e outras verificações diversas também acontecem. A saída do analisador é um DAG. Esse DAG é passado para o Optimizer, que executa otimização lógica, como projeção e empurra para baixo. Em seguida, o compilador cumpre o plano lógico para os trabalhos do MapReduce. Por fim, essas tarefas do MapReduce são enviadas ao Hadoop em ordem classificada. Esses trabalhos são executados e produzem os resultados desejados.
O modelo de dados do Pig-Latin está totalmente aninhado e permite tipos de dados complexos, como mapa e tupla.
Qualquer valor único do idioma latino do Pig (independentemente do tipo de dados) é conhecido como Atom.
Comandos Básicos do Pig
Vamos dar uma olhada em alguns dos comandos do Basic Pig que são dados abaixo: -
1. Fs: Isso listará todo o arquivo no HDFS
grunhido> fs –ls
2. Limpar: Isso limpará o shell Grunt interativo.
grunhido> claro
3. História:
Este comando mostra os comandos executados até o momento.
grunhido> história
4. Lendo dados: Supondo que os dados residam no HDFS, e precisamos ler os dados no Pig.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
USANDO PigStorage (', ')
as (id: int, nome: chararray, sobrenome: chararray, telefone: chararray,
cidade: chararray);
PigStorage () é a função que carrega e armazena dados como arquivos de texto estruturados.
5. Armazenando Dados: O operador Store é usado para armazenar os dados processados / carregados.
grunt> STORE college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USANDO PigStorage (', ');
Aqui, “/ pig_Output /” é o diretório em que a relação precisa ser armazenada.
6. Operador de despejo: Este comando é usado para exibir os resultados na tela. Geralmente ajuda na depuração.
grunhido> Dump college_students;
7. Descrever Operador: Ajuda o programador a visualizar o esquema da relação.
grunhido> descreva estudantes universitários;
8. Explique: Este comando ajuda a revisar os planos de execução lógicos, físicos e de redução de mapa.
grunhir> explicar estudantes universitários;
9. Ilustrar operador: fornece execução passo a passo de instruções nos comandos Pig.
grunhir> ilustrar universitários;
Comandos intermediários de porco
1. Grupo: Este comando Pig trabalha para agrupar dados com a mesma chave.
grunhido> group_data = GRUPO college_students pelo primeiro nome;
2. COGROUP: Funciona de maneira semelhante ao operador do grupo. A principal diferença entre o operador de grupo e grupo de grupo é o operador de grupo geralmente usado com uma relação, enquanto o grupo de grupo é usado com mais de uma relação.
3. Unir: É usado para combinar duas ou mais relações.
Exemplo: para executar a auto-junção, digamos que a relação "customer" seja carregada dos comandos HDFS tp pig em duas relações customers1 & customers2.
grunt> customers3 = JOIN customers1 BY id, customers2 BY id;
A junção pode ser de auto-junção, interna ou externa.
4. Cruz: Este comando pig calcula o produto cruzado de duas ou mais relações.
grunhido> cross_data = CROSS clientes, pedidos;
5. União: Funde duas relações. A condição para mesclar é que as colunas e os domínios da relação devem ser idênticos.
grunhido> aluno = UNIÃO aluno1, aluno2;
Comandos avançados do Pig
Vamos dar uma olhada em alguns dos comandos avançados do Pig, que são dados abaixo:
1. Filtro: Isso ajuda a filtrar as tuplas fora de relação, com base em determinadas condições.
filter_data = FILTER college_students BY city == 'Chennai';
2. Distinto: Isso ajuda na remoção de tuplas redundantes da relação.
grunhido> dados_distintos = DISTINCT estudantes_ universitários;
Essa filtragem criará um novo nome de relação "dados_ distintos"
3. Foreach: Isso ajuda na geração de transformação de dados com base nos dados da coluna.
grunhido> foreach_data = FOREACH student_details GERAR ID, idade, cidade;
Isso obterá os valores de identificação, idade e cidade de cada aluno da relação student_details e, portanto, o armazenará em outra relação denominada foreach_data.
4. Ordenar por: Este comando exibe o resultado em uma ordem classificada com base em um ou mais campos.
grunhido> order_by_data = ORDEM universitários POR idade DESC;
Isso classificará a relação "college_students" em ordem decrescente por idade.
5. Limite: Este comando fica limitado não. de tuplas da relação.
grunt> limit_data = LIMIT student_details 4;
Dicas e truques
Abaixo estão as diferentes dicas e truques dos comandos do Pig: -
1. Ative a compactação na sua entrada e saída:
defina input.compression.enabled true;
defina output.compression.enabled true;
As linhas de código acima mencionadas devem estar no início do script, para permitir que os comandos do Pig leiam arquivos compactados ou gerem arquivos compactados como saída.
2. Junte-se a várias relações:
Para executar a junção esquerda em, digamos, três relações (entrada1, entrada2, entrada3), é necessário optar pelo SQL. Isso ocorre porque a junção externa não é suportada pelo Pig em mais de duas tabelas.
Em vez disso, você executa a esquerda para participar em duas etapas, como:
data1 = JOIN entrada1 pela tecla ESQUERDA, entrada2 pela tecla;
data2 = JOIN data1 BY entrada1 :: tecla ESQUERDA, entrada3 tecla BY ;
Isso significa dois trabalhos de redução de mapa.
Para executar a tarefa acima com mais eficiência, pode-se optar por "Grupo". O Cogroup pode unir várias relações. O grupo de grupo, por padrão, faz a junção externa.
Conclusão
O porco é uma linguagem processual, geralmente usada pelos cientistas de dados para realizar processamento ad-hoc e prototipagem rápida. É uma ótima ferramenta de processamento de ETL e big data. Os scripts do Pig podem ser chamados por outros idiomas e vice-versa. Portanto, os comandos Pig podem ser usados para criar aplicativos maiores e complexos.
Artigos recomendados
Este foi um guia para os comandos do Pig. Aqui discutimos comandos básicos e avançados do Pig e alguns comandos imediatos do Pig. Você também pode consultar o seguinte artigo para saber mais -
- Comandos do Adobe Photoshop
- Comandos do Tableau
- Cábula SQL (comandos, dicas grátis e truques)
- Toques de finalização de comandos do VBA
- Diferentes operações relacionadas a Tuplas