

Introdução às perguntas e respostas da entrevista RDBMS
Portanto, se você está se preparando para uma entrevista de emprego no RDBMS. Tenho certeza de que deseja saber as perguntas e respostas mais comuns da entrevista RDBMS 2019 que ajudarão você a quebrar a entrevista RDBMS com facilidade. Abaixo está a lista das principais perguntas e respostas da entrevista RDBMS em seu resgate.
Portanto, tendemos a adicionar as principais perguntas da entrevista do RDBMS 2019, que são feitas principalmente em uma entrevista
1. Quais são os diferentes recursos de um RDBMS?
Responda:
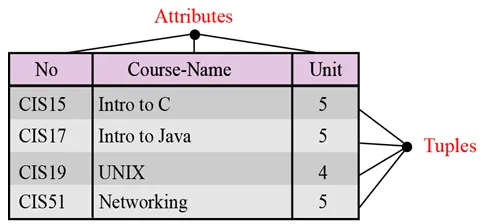
Nome. Toda relação em um banco de dados relacional deve ter um nome exclusivo entre todas as outras relações.
Atributos. Cada coluna em uma relação é chamada de atributo.
Tuplas. Cada linha de uma relação é chamada de tupla. Uma tupla define uma coleção de valores de atributos.
2.Explique o modelo de ER?
Responda:
O modelo ER é um modelo de Entidade-Relacionamento. O modelo de ER é baseado em um mundo real composto de entidades e objetos de relacionamento. As entidades são ilustradas em um banco de dados por um conjunto de atributos.
3.Definir modelo orientado a objeto?
Responda:
O modelo orientado a objetos é baseado em coleções de objetos. Um objeto acomoda valores armazenados em variáveis de instância dentro do objeto. Objetos com um tipo idêntico de valores e exatamente os mesmos métodos são agrupados em classes.
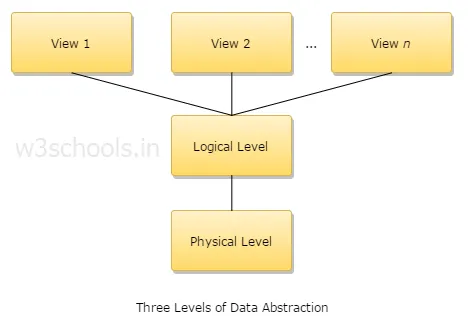
4. Explique três níveis de abstração de dados?
Responda:
1. Nível físico: este é o nível mais baixo de abstração e descreve como os dados são armazenados.
2. Nível lógico: o próximo nível de abstração é lógico, descreve que tipo de dados são armazenados em um banco de dados e qual é o relacionamento entre esses dados.
3. Nível de visualização: o nível mais alto de abstração e descreve o único banco de dados inteiro.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5. Quais são as 12 regras do Codd para o Banco de Dados Relacional?
Responda:
As 12 regras de Codd são um conjunto de treze regras (numeradas de zero a doze) propostas por Edgar F. Codd.
Regras do Codd: -
Regra 0: O sistema deve se qualificar como Relacional, como Banco de Dados e também como Sistema de Gerenciamento.
Regra 1: A regra de informações: Toda e qualquer informação no banco de dados deve ser representada exclusivamente, principalmente o nome de valores nas posições das colunas em uma linha diferente de uma tabela.
Regra 2: A regra de acesso garantido: todos os dados devem ser ingressivos. Ele diz que todo valor escalar no banco de dados deve ser corretamente / logicamente endereçável.
Regra 3: Tratamento sistemático de valores nulos: O DBMS deve permitir que cada tupla permaneça nula.
Regra 4: Catálogo on-line ativo (estrutura do banco de dados) com base no modelo relacional: O sistema deve suportar uma estrutura on-line, relacional etc., que seja acessível aos usuários permitidos por meio de suas consultas regulares.
Regra 5: A sub-linguagem abrangente de dados: O sistema deve auxiliar no mínimo uma linguagem relacional que:
1.Tem uma sintaxe linear
2.Que pode ser usado tanto de forma interativa quanto dentro de programas aplicativos,
3. Suporta operações de definição de dados (DDL), operações de manipulação de dados (DML), restrições de segurança e integridade e operações de gerenciamento de transações (início, confirmação e reversão).
Regra 6: A regra de atualização de visualizações: Todas as visualizações que teoricamente melhoram devem ser atualizadas pelo sistema.
Regra 7: Inserção, atualização e exclusão de alto nível: O sistema deve suportar operadores de inserção, atualização e exclusão.
Regra 8: Independência de dados físicos: modifique o nível físico (como os dados são armazenados, usando matrizes ou listas vinculadas etc.) não deve exigir uma modificação em um aplicativo.
Regra 9: Independência de dados lógicos: modifique o nível lógico (tabelas, colunas, linhas etc.) não deve exigir uma modificação em um aplicativo.
Regra 10: Independência da integridade: as restrições de integridade devem ser identificadas individualmente nos programas aplicativos e armazenadas no catálogo.
Regra 11: Independência da distribuição: a distribuição de partes de um banco de dados para locais diferentes não deve ser visível para os usuários do banco de dados.
Regra 12: A regra de não submissão: Se o sistema fornecer uma interface de baixo nível (ou seja, registros), essa interface não poderá ser usada para subverter o sistema.
6.O que é normalização? e o que explica diferentes formas de normalização.
Responda:
A normalização do banco de dados é um processo de organização de dados para minimizar a redundância de dados. O que, por sua vez, garante a consistência dos dados. Existem muitos problemas associados à redundância de dados, como desperdício de espaço em disco, inconsistência de dados e consultas DML (Data Manipulation Language) que ficam lentas. Existem diferentes formas de normalização: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Os dados em cada coluna devem ser números atômicos com vários valores separados por vírgula. A tabela não contém nenhum grupo de colunas repetidas. Identifique cada registro exclusivamente usando a chave primária.
2. 2NF: - A tabela deve corresponder a todas as condições de 1NF e mover dados redundantes para separar a tabela. Além disso, ele cria um relacionamento entre essas tabelas usando chaves estrangeiras.
3. 3NF: - para uma tabela 3NF deve cumprir todas as condições de 1NF e 2NF. 3NF não contém atributos parcialmente dependentes da chave primária.
7.Define chave primária, chave estrangeira, chave candidata, super chave?
Responda:
Chave primária : chave primária é a chave que não permite valores duplicados e valores nulos. Uma chave primária pode ser definida no nível da coluna ou da tabela. Somente uma chave primária por tabela é permitida.
Chave estrangeira : chave estrangeira permite apenas os valores presentes na coluna referenciada. Permite valores duplicados ou nulos. Pode ser definido como o nível da coluna ou da tabela. Ele pode fazer referência a uma coluna de uma chave exclusiva / primária.
Chave do candidato: Uma chave do candidato é uma super chave mínima, não há subgrupo adequado de atributos da chave do candidato que pode ser uma super chave.
Superchave : Uma superchave é um conjunto de atributos de um esquema de relação do qual todos os atributos do esquema são parcialmente dependentes. Nenhuma duas linhas podem ter o mesmo valor de atributos de super chave.
8.O que é um tipo diferente de índices?
Responda:
Os índices são: -
Índice em cluster: - É o índice no qual os dados são fisicamente armazenados no disco. Portanto, apenas um índice em cluster pode ser criado para uma tabela de banco de dados.
Índice não agrupado: - Ele não define dados físicos, mas define uma ordem lógica. Normalmente, B-Tree ou B + tree são criadas para esse fim.
9. Quais são as vantagens do RDBMS?
Responda:
• Controlando a redundância.
• A integridade pode ser imposta.
• Inconsistência pode ser evitada.
• Os dados podem ser compartilhados.
• O padrão pode ser imposto.
10.Nome de alguns subsistemas do RDBMS?
Responda:
Entrada-saída, Segurança, Processamento de idiomas, Gerenciamento de armazenamento, Registro e recuperação, Controle de distribuição, Controle de transações, Gerenciamento de memória.
11. O que é o Buffer Manager?
Responda:
O Buffer Manager consegue coletar dados do armazenamento em disco para a memória principal e decidir quais dados devem estar na memória cache para um processamento mais rápido.
Artigo recomendado
Este foi um guia para a lista de perguntas e respostas da entrevista RDBMS, para que o candidato possa reprimir essas perguntas da entrevista RDBMS facilmente. Você também pode consultar os seguintes artigos para saber mais -
- Perguntas mais importantes da entrevista de análise de dados
- 13 perguntas e respostas surpreendentes da entrevista sobre testes de banco de dados
- Top 10 Perguntas e respostas sobre entrevistas com padrões de design
- 5 perguntas e respostas úteis da entrevista do SSIS