

Introdução à Arquitetura HBase
O HBase é um sistema de armazenamento de dados de valor-chave distribuído de código aberto e banco de dados orientado a colunas com alta saída de gravação e desempenho de leitura aleatória de baixa latência. Usando o HBase, podemos realizar análises on-line em tempo real. A arquitetura do HBase possui forte legibilidade aleatória. No HBase, os dados são agrupados fisicamente no que é conhecido como regiões. Cada região é hospedada por um servidor de região única e uma ou mais regiões são responsáveis por cada servidor de região. A arquitetura HBase é composta por servidores master-slave. O cluster HBase possui um nó mestre chamado HMaster e vários servidores de região chamados HRegion Server (HRegion Server). Existem várias regiões - regiões em cada servidor regional.
Mecanismo de armazenamento HDFS

No HDFS, os dados são armazenados na tabela como mostrado acima.
Cada linha tem uma chave.
Coluna: é uma coleção de dados que pertence a uma família de colunas e é incluída dentro da linha.
Família de colunas: cada família de colunas consiste em uma ou mais colunas.
Cada tabela contém uma coleção de famílias de colunas. Essas colunas não fazem parte do esquema.
O HBase possui colunas dinâmicas. Células diferentes podem ter colunas diferentes porque os nomes das colunas são codificados dentro das células
Qualificador da coluna: o nome da coluna é conhecido como qualificador da coluna.
Componentes da arquitetura HBase
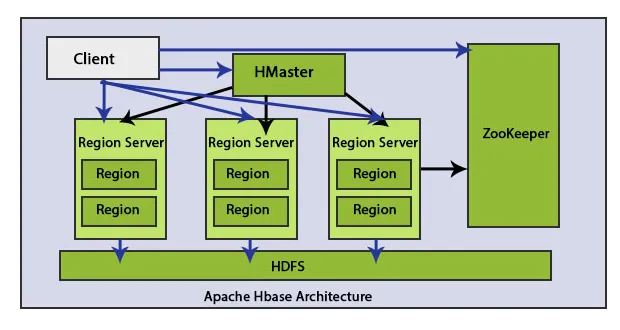
Existem elementos principais na arquitetura do HBase: HMaster e Region Server. Dados regionais de salvamento do HBase.
1. HMaster
O nó HMaster é leve e usado para atribuir a região à região do servidor.
Existem algumas responsabilidades principais da Hmaster que são:
- Realização de algumas tarefas administrativas, incluindo carregamento, balanceamento, criação de dados, atualização, exclusão etc.
Responsável por alterações no esquema ou modificações nos dados META de acordo com a direção do aplicativo cliente
- Muito trabalho DDL nas tabelas HBase é tratado pelo HMaster.
Alguns dos métodos expostos pela Interface HMaster são principalmente. Métodos orientados a dados META.
- Tabela (criar, remover, ativar, desativar, remover tabela)
- ColumnFamily (adicionar coluna, modificar coluna)
- Região (mover, atribuir)
O cliente se comunica com o HMaster e o ZooKeeper bidirecionalmente. Ele entra em contato diretamente com os servidores HRegion para ler e gravar operações. O HMaster atribui regiões a servidores na região e, por sua vez, verifica o status de integridade dos servidores regionais.
2. Servidor de Região
Podemos ter uma idéia aproximada do servidor da região através de um diagrama abaixo.

Os servidores de região são nós de trabalho que lidam com as solicitações dos clientes para leitura, gravação, atualização e exclusão. O Region Server é leve, é executado em todos os nós no cluster Hadoop. A principal tarefa do servidor da região é salvar os dados em áreas e executar solicitações de clientes. Outra tarefa importante do HBase Region Server é usar o método Auto-Sharding para executar o balanceamento de carga distribuindo dinamicamente a tabela HBase quando ela se tornar muito grande após a inserção de dados.
Vários servidores HRegion podem ser contatados pelo HMaster e executar as seguintes funções:
- Hospedagem de gerenciamento e regiões
- Dividir regiões automaticamente
- Tratamento de pedidos de leitura e escrita
- Comunicação direta com o cliente
3. HDFS
HDFS significa o sistema de arquivos distribuídos do Hadoop. Ele armazena todos os arquivos em vários blocos e replica blocos em um cluster Hadoop para manter a tolerância a falhas. O HDFS oferece alta tolerância a falhas e trabalha com materiais de baixo custo. Ao usar um hardware de commodity barato para adicionar nós ao cluster e processar e salvar, ele fornecerá ao cliente melhores resultados do que o hardware existente. O HDFS entra em contato com os componentes do HBase e salva muitos dados de maneira distribuída.
4. tratador
O Zookeeper é um projeto de código aberto. O HMaster e o HRegionServers se registram no ZooKeeper.
Ele fornece vários serviços, como manter informações de configuração, nomear, fornecer sincronização distribuída, etc. A Sincronização Distribuída é o processo de fornecer serviços de coordenação entre os nós para acessar os aplicativos em execução. Possui nós efêmeros que representam servidores da região. Servidores principais usam esses nós para procurar servidores disponíveis.
Esses nós também são usados para rastrear partições de rede e falhas do servidor. O Zookeeper é o meio de interação entre o servidor da região do Cliente. Se um cliente deseja se comunicar com o servidor da região, o zookeeper é o meio de comunicação entre eles.
Como a pesquisa inicializa na arquitetura HBase
Como você sabe, o local da tabela META é salvo pelo Zookeeper. Sempre que um cliente se aproxima ou grava solicitações do HBase, o procedimento é o seguinte.
O cliente descobre no ZooKeeper como colocá-los na tabela META. O cliente solicita a chave de linha apropriada da tabela META para acessar o local do servidor da região. Com a localização da tabela META, o cliente armazena em cache essas informações. O cliente não deve se referir a elas na tabela META até e se a área for movida ou deslocada. Em seguida, o servidor META será solicitado novamente e o cache será atualizado. Como sempre, os clientes não perdem tempo encontrando o local do servidor de região no META Server, economizando tempo e agilizando o processo de pesquisa.
Recursos
É fácil integrar a partir da origem e do destino com o Hadoop.
O armazenamento distribuído como HDFS é suportado.
Ele possui um recurso de acesso aleatório usando uma Tabela Hash interna para armazenar dados para pesquisas mais rápidas em arquivos HDFS.
Vantagens da arquitetura HBase
- Eles podem armazenar grandes conjuntos de dados
- Nós podemos compartilhar o banco de dados
- Gigabytes para petabytes com boa relação custo-benefício
- Alta disponibilidade através de replicação e falha
Desvantagens da arquitetura HBase
- Estrutura SQL não suporta
- Não suporta transação
- Somente com a chave classificada
- Problemas de memória de cluster
Conclusão
O HBase é um dos bancos de dados distribuídos orientados a colunas NonSql no apache. Ao comparar com o Hadoop ou o Hive, o HBase tem um desempenho melhor para recuperar menos registros. Portanto, neste artigo, discutimos a arquitetura do HBase e seus componentes importantes.
Artigos recomendados
Este foi um guia para a arquitetura HBase. Aqui discutimos o conceito, componentes, recursos, vantagens e desvantagens. Você também pode acessar nossos outros artigos sugeridos para saber mais -
- O que é a tecnologia de Big Data?
- HDFS vs HBase Qual é o melhor
- O que é a linguagem Assembly?
- Introdução ao HTML