

Introdução ao AWS EMR
O AWS EMR fornece muitas funcionalidades que facilitam as coisas para nós, algumas das tecnologias são:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
Um dos principais serviços fornecidos pela AWS EMR e com os quais vamos lidar é o Amazon EMR.
O EMR comumente chamado Elastic Map Reduce vem com uma maneira fácil e acessível de lidar com o processamento de grandes pedaços de dados. Imagine um cenário de big data em que temos uma quantidade enorme de dados e estamos realizando um conjunto de operações sobre eles, digamos que um trabalho de redução de mapa esteja em execução, um dos principais problemas que o aplicativo Bigdata enfrenta é o ajuste do programa, nós geralmente, é difícil ajustar nosso programa de maneira que todo o recurso alocado seja consumido adequadamente. Devido a esse fator de ajuste acima, o tempo necessário para o processamento aumenta gradualmente. O Elastic Map Reduce the service da Amazon é um serviço da Web que fornece uma estrutura que gerencia todos esses recursos necessários para o processamento de Big Data de maneira econômica, rápida e segura. Desde a criação do cluster até a distribuição de dados em várias instâncias, tudo isso é gerenciado facilmente no Amazon EMR. Os serviços aqui são sob demanda significa que podemos controlar os números com base nos dados que temos, que se tornam econômicos e escaláveis.
Razões para usar o AWS EMR
Então, por que usar a AMR o que a torna melhor para os outros. Muitas vezes, encontramos um problema muito básico, onde somos incapazes de alocar todos os recursos disponíveis no cluster para qualquer aplicativo, o AMAZON EMR cuidando desses problemas e com base no tamanho dos dados e na demanda do aplicativo que aloca o recurso necessário. Além disso, sendo elástico por natureza, podemos alterá-lo de acordo. O EMR tem um suporte enorme a aplicativos, seja no Hadoop, Spark, HBase, que facilita o processamento de dados. Ele suporta várias operações ETL de forma rápida e econômica. Também pode ser usado para MLIB no Spark. Podemos executar vários algoritmos de aprendizado de máquina dentro dele. Seja dados em lote ou Streaming de dados em tempo real, o EMR é capaz de organizar e processar os dois tipos de dados.
Trabalho do AWS EMR
Agora vamos ver este diagrama do cluster do Amazon EMR e tentar entender como ele realmente funciona:
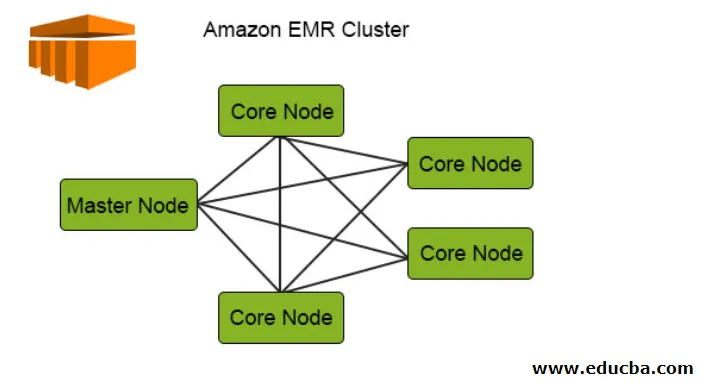
O diagrama a seguir mostra a distribuição do cluster do EMR interno. Vamos verificar isso em detalhes:
1. Os Clusters são o componente central da arquitetura do Amazon EMR. Eles são uma coleção de instâncias do EC2 chamadas Nós. Cada nó tem suas funções específicas no cluster denominadas como tipo de nó e, com base em suas funções, podemos classificá-las em 3 tipos:
- Nó Mestre
- Nó Principal
- Nó de Tarefas
2. O nó principal, como o nome sugere, é o principal responsável pelo gerenciamento do cluster, executando os componentes e a distribuição de dados pelos nós para processamento. Ele apenas controla se tudo está gerenciado e funcionando adequadamente e funciona em caso de falha.
3. O Nó Principal tem a responsabilidade de executar a tarefa e armazenar os dados no HDFS no cluster. Todas as peças de processamento são tratadas pelo Nó principal e os dados após esse processamento são colocados no local HDFS desejado.
4. O nó de tarefa, sendo opcional, tem apenas a tarefa de executar a tarefa, que não armazena os dados no HDFS.
5. Sempre que após enviar um trabalho, temos vários métodos para escolher como os trabalhos precisam ser concluídos. Desde o término do cluster após a conclusão do trabalho até um cluster de longa execução usando o console EMR e a CLI para enviar as etapas, temos todo o privilégio de fazê-lo.
6. Podemos executar o trabalho diretamente no EMR conectando-o ao nó mestre por meio das interfaces e ferramentas disponíveis que executam os trabalhos diretamente no cluster.
7. Também podemos executar nossos dados em várias etapas com a ajuda do EMR, tudo o que precisamos fazer é enviar uma ou mais etapas ordenadas no cluster EMR. Os dados são armazenados como um arquivo e são processados de maneira seqüencial. Iniciando-o de “estado pendente para estado concluído”, podemos rastrear as etapas de processamento e encontrar os erros também em 'Falha ao ser cancelado'. Todas essas etapas podem ser facilmente rastreadas até isso.
8. Depois que toda a instância é encerrada, é alcançado o estado concluído para o cluster.
Arquitetura para AWS EMR
A arquitetura do EMR se apresenta a partir da parte de armazenamento para a parte Aplicativo.
- A primeira camada vem com a camada de armazenamento, que inclui diferentes sistemas de arquivos usados com nosso cluster. Seja do HDFS ao EMRFS, ao sistema de arquivos local, todos eles são usados para armazenamento de dados em todo o aplicativo. O armazenamento em cache dos resultados intermediários durante o processamento do MapReduce pode ser alcançado com a ajuda dessas tecnologias que acompanham o EMR.
- A segunda camada é fornecida com o Gerenciamento de recursos do cluster. Essa camada é responsável pelo gerenciamento de recursos dos clusters e nós do aplicativo. Isso basicamente ajuda como as ferramentas de gerenciamento que ajudam a distribuir uniformemente os dados pelo cluster e o gerenciamento adequado. A ferramenta Gerenciamento de recursos padrão que o EMR usa é o YARN que foi introduzido no Apache Hadoop 2.0. Ele gerencia centralmente os recursos para várias estruturas de processamento de dados. Ele cuida de todas as informações necessárias para o bom funcionamento do cluster, desde a integridade do nó até a distribuição de recursos com gerenciamento de memória.
- A Terceira camada vem com a Estrutura de processamento de dados, essa camada é responsável pela análise e pelo processamento dos dados. existem muitas estruturas suportadas pelo EMR que desempenham um papel importante no processamento de dados paralelo e eficiente. Algumas das estruturas suportadas e conhecidas são: APACHE HADOOP, SPARK, SPARK STREAMING, etc.
- A quarta camada vem com o aplicativo e programas como HIVE, PIG, biblioteca de streaming, algoritmos de ML que são úteis para processar e gerenciar grandes conjuntos de dados.
Vantagens do AWS EMR
Vamos agora verificar alguns dos benefícios do uso do EMR:
- Alta velocidade: como todos os recursos são utilizados adequadamente, o tempo de processamento da consulta é comparativamente mais rápido do que as outras ferramentas de processamento de dados têm uma imagem muito clara.
- Processamento em massa de dados: Seja maior o tamanho dos dados que o EMR tem a capacidade de processar uma grande quantidade de dados em tempo suficiente.
- Perda mínima de dados: como os dados são distribuídos pelo cluster e processados paralelamente pela rede, há uma chance mínima de perda de dados e, assim, a taxa de precisão dos dados processados é melhor.
- Custo-benefício: Por ser econômico, é mais barato do que qualquer outra alternativa disponível, o que o torna forte em relação ao uso do setor. Como o preço é menor, podemos acomodar grandes quantidades de dados e processá-los dentro do orçamento.
- AWS Integrado: É integrado a todos os serviços da AWS que facilita a disponibilidade sob um teto, para que a segurança, o armazenamento e a rede estejam integrados em um único local.
- Segurança: Ele vem com um incrível grupo de Segurança para controlar o tráfego de entrada e saída e também o uso de Funções do IAM o torna mais seguro, pois possui várias permissões para proteger os dados.
- Monitoramento e implantação: temos ferramentas de monitoramento adequadas para todos os aplicativos executados em clusters de EMR, o que o torna transparente e fácil para a parte de análise, além de um recurso de implantação automática, em que o aplicativo é configurado e implantado automaticamente.
Há muito mais vantagens em ter o EMR como uma melhor escolha para outro método de computação em cluster.
Preços do AWS EMR
O EMR vem com uma incrível lista de preços que atrai desenvolvedores ou o mercado a ele. Como ele vem com um recurso de preços sob demanda, podemos usá-lo a cada hora e número de nós em nosso cluster. Podemos pagar uma taxa por segundo por cada segundo que usamos com um minuto no mínimo. Também podemos escolher nossas instâncias para serem usadas como Instâncias reservadas ou Instâncias spot, o que economiza muito nos custos.
Podemos calcular a conta total usando uma calculadora mensal simples no link abaixo: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
Para obter mais detalhes sobre os detalhes exatos de preços, consulte o documento abaixo na Amazon: -
https://aws.amazon.com/emr/pricing/
Conclusão
No artigo acima, vimos como o EMR pode ser usado para o processamento justo de big data, com todos os recursos sendo utilizados convencionalmente.
Ter o EMR resolve nosso problema básico de processamento de dados e reduz muito o tempo de processamento por um bom número, sendo econômico, é fácil e conveniente de usar.
Artigo recomendado
Este foi um guia para o AWS EMR. Aqui discutimos uma introdução ao AWS EMR ao longo de seu trabalho e arquitetura, além das vantagens. Você também pode consultar nossos outros artigos sugeridos para saber mais -
- Alternativas da AWS
- Comandos da AWS
- Serviços da AWS
- Perguntas da entrevista da AWS
- Serviços de armazenamento da AWS
- Os 7 principais concorrentes da AWS
- Lista de recursos do Amazon Web Services